我對 Ackermann's function (艾克曼函數)一直有著強烈的崇敬感。
讓我們先從兩個簡單的函數看起。如果 f(n) = n
n,那麼 f(0) = 1, f(1) = 1, f(2) = 2
2, f(3) = 3
3, ..., 它增長的速率是相當快的(也就是說,f(n+1) 會比 f(n) 的值要大上大頗多)。而如果 g(n) = n
n...n(共有 n 項),我們應該會對 g(n) 的增長速率感到些許敬畏、感到有些「遙不可及」。
可以想像,應該會有增長速率更快的函數。例如,Knuth 就曾提出一種
big-number(很大的數目)的表示法(注意到,這套表示法會用到無限多個(^, ^^, ^^^, ... )運算子;而且這些運算子都是右結合(right associative)的,例如 2
34 = 2
(34) = 2
81):
m ^ n = m m ... m (n 項) = m n
m^^n = m^m^...^m (n 項) = mm...m
m^^^n = m^^m^^...^^m (n 項)
Ackermann's function 的定義很簡單:
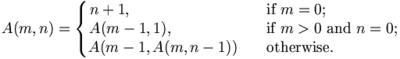
它簡單到用程式實作,幾乎只要照著定義抄就可以了。例如,以下就是一個用 PHP 實作的程式,它可以算出 A(3, 6) = 509:
<?php
function A($m, $n) {
if ($m == 0) return ($n + 1);
else {
if ($n == 0) return A($m-1, 1);
else return A($m-1, A($m, $n-1));
}
}
print "A(3, 6) = " . A(3, 6);
?>
令人驚訝的是,Ackermann's function 增長的速度非常快。現在的電腦威力已經很強了,但是要計算 A(4, 2) --- 更不用說是計算 A(5, 1) 了 --- 都還是會出現 Stack Overflow 或者 Out Of Memory 的錯誤訊息。事實上,Ackermann's function 增長的速度,比
m^n、
m^^n、甚至
m^^^n 都還要快。在數學上,它是一個 total recursive(全然迴歸:對於每個自然數 m, n,A(m, n) 都有定義)的函數,但是卻不是一個
primitive recursive(基本迴歸)函數。它增長的速度,遠超過一般人所能想像。
這也沒什麼嘛,數學的世界裡,本來就有許多令人驚詫的函數或定理,不是嗎?
是這樣的。十餘年前修習數理邏輯時,老師把「證明 Ackermann's function 非 primitive recursive」當成作業給學生做。那位老師 (Dr. Kueker) 很有趣,習題做錯後,他會點出錯誤所在(有時還會給一點提示),然後學生可以在學期內任何時刻再補交(如果還是做錯,可以下回再繼續補交)。重點是,這題我「證明」了三次,但每次都是錯的。一直到學期末,我想破了頭,都沒有證明出來。
也因為曾經努力數個月卻還是失敗,我對 Ackermann's function 一直有著頗為複雜的情感。有時,我會覺得:人就是這樣,對於盡力後依然失敗的情事,日後反而會留下最深刻的印象。






















{kind=link}
{kind=link}