芝諾 (Zeno) 曾提出一個有名的「烏龜悖論」。
希臘戰士阿基里斯跟烏龜賽跑。烏龜說,如果牠比阿基里斯先跑10公尺,那麼阿基里斯永遠都追不上牠。因為只要阿基里斯跑了10公尺,這時烏龜就又多跑了幾公尺;若阿基里斯再跑到烏龜曾經停留的點,烏龜一定又跑到阿基里斯前面去了... 如此這般,阿基里斯永遠追不上烏龜。
這悖論 (paradox) 之所以引人入勝,一個主要原因是:它看似有理,但我們卻很清楚地知曉以上的論證必有錯。用腳趾頭想也知道,善跑者怎麼可能追不上烏龜?
問題是,我們該如何說明論證的錯誤點。先撇開這個悖論中的「時空」觀念(據說,這部分仍然引發學者的爭辯),許多人同意羅素的看法:「從 Cantor 之後,在邏輯上才解決了這個悖論」。
嗯,Cantor 的確是說明了,無窮級數的和,並不一定是無窮大(可能收斂在某個數)。但... 等等,這和悖論的論證,又有什麼關係呢?
原來,論證的錯誤在於:前面的無窮個推論(每當阿基里斯跑到烏龜曾停留的點,烏龜就又往前跑了一小段路),並不能推導出「如此這般,阿基里斯永遠追不上烏龜」的結論。
換句話說,雖然每一步的推論的確都沒有錯,也「看得出來」每一步的推論,都讓阿基里斯與烏龜又多跑了一小段路,但即使有無窮多個「向前推進」的正確推論,我們仍然無法得出「追不上烏龜」的結論。
於是,邏輯上,要證明某項結論,必須經由有限個推理步驟。利用無限個逼近步驟所推得的結論,在邏輯上是無效的。
星期六, 11月 26, 2005
朝三暮四
朝三暮四,是一則歷久彌新、發人深省的寓言。
我想,莊子真是個細心的人。他竟然觀察到,春秋時期,猴子就已經很聰明了。牠們知道:先拿到的先贏。早上先拿到栗子,即使不拿去投資,把栗子儲存起來,得到的樂趣也(比晚上再拿到)更多!
究竟是猴子愚魯,不知道「3 + 4 = 4 + 3」;狙公狡猾(或聰明),懂得搬弄「朝三暮四、朝四暮三」來取悅猴子;還是猴子竟比想像中的還要聰明,知道先取先贏(很像社會現況呢)的道理?
感覺寓言的巧妙,有時竟可從不同角度、不同層次,得到不同的解讀。莊子真的很有智慧。
狙公賦芧,曰:『朝三而暮四。』眾狙皆怒。曰:『然則朝四而暮三。』眾狙皆悅。
---《莊子‧齊物論》
我想,莊子真是個細心的人。他竟然觀察到,春秋時期,猴子就已經很聰明了。牠們知道:先拿到的先贏。早上先拿到栗子,即使不拿去投資,把栗子儲存起來,得到的樂趣也(比晚上再拿到)更多!
究竟是猴子愚魯,不知道「3 + 4 = 4 + 3」;狙公狡猾(或聰明),懂得搬弄「朝三暮四、朝四暮三」來取悅猴子;還是猴子竟比想像中的還要聰明,知道先取先贏(很像社會現況呢)的道理?
感覺寓言的巧妙,有時竟可從不同角度、不同層次,得到不同的解讀。莊子真的很有智慧。
星期四, 11月 24, 2005
談古契書資料處理:之三
要做好資訊處理,必須對「欲處理的資訊內容」有些最起碼的認識。
很不幸(或很幸運 --- 因為問題難纏,所以很少人願意花力氣去做)地,一般的古籍,是沒有標點符號的。一篇沒有標注逗點、句點符號的文章,看起來可是有夠令人氣餒的。
不信?請看這一小段摘錄下來的「古地契」:
要處理古契書,多多少少就得花些時間看看這些契書的內容、並看看它們有沒有一些可資利用的樣式(patterns)。不過,一般資訊人(嗯,或許是阿尼說的「資遜人」?)看到像這樣未經標注的古文,沒有昏倒、也很難著性子看完幾篇吧。
適當的標注,也會影響到文章的解讀。就像是著名的「下雨天留客天天留我不留」,加上不同的標注後,可以產生迥然不同的解釋:「下雨天、留客天,天留、我不留」、「下雨天留客,天天留我不?留」。
碰到這類棘手的問題,一種方式是花錢請「專家」來標注。好吧,就算我們請一些「歷史系的專家或學生們」來對一些古文加上標注,也假設他們的標注是可接受的;接下來也還是會遇到中文處理的許多困難,其中之一就是「斷詞」。
一般來說,中英文都沒有斷字的問題。英文嘛,一個「字」(word) 是由 a, b, c 等英文字母組成,字與字之間可由空白、逗點等來區隔。例如,"This is a book." 這個句子,其中 "this"、 "is"、"a"、"book" 都是個別的「字」。而中文由於是方塊字,每一個字有獨立的字碼,也沒有斷字的問題。
但是,在中文裡,個別看每一個字,通常對內文的了解沒有什麼幫助;數個字連接起來成為一個「詞」之後,這個詞才會具備特定的意義。例如,「新」、「竹」如果分開來看,與「新竹」的意義,經常是完全不同的。
所以,中文有斷詞的問題。在前頭舉的古地契例子裡,「山埔」、「田薗」、「南港」、「鹿廚溪」都可以算作獨立的「詞」;但看起來像是個人名的「黃鼎愛斯」呢?是該斷作「黃鼎愛」、還是「黃鼎愛斯」?
可以想見,適當的標注,有助於斷詞的正確性。至少,我們知道一個詞不應橫跨由標點符號隔開的兩個子句。但是,即使有加上標點,想要適當地斷詞 --- 甚至斷出「地理名詞」、「人名」等特殊意義的詞彙 --- 都還是一項艱難的挑戰。
很不幸(或很幸運 --- 因為問題難纏,所以很少人願意花力氣去做)地,一般的古籍,是沒有標點符號的。一篇沒有標注逗點、句點符號的文章,看起來可是有夠令人氣餒的。
不信?請看這一小段摘錄下來的「古地契」:
立杜賣斷根山埔田薗字人黃鼎愛斯先年承買有山埔地壹所坐落土名南港鹿廚溪尾四至界址載在總契詳明金因乏銀別立母特此地東片拆開壹角東至陳家小溪田崁直上龍崗倒水為界西至波塘下帶田壹大坵左君子田唇毗連直透橫崗倒水為界南至左君子会埔直透大凸為界北至伯公艮直透洽溪為界四至界址同中面踏分明...
要處理古契書,多多少少就得花些時間看看這些契書的內容、並看看它們有沒有一些可資利用的樣式(patterns)。不過,一般資訊人(嗯,或許是阿尼說的「資遜人」?)看到像這樣未經標注的古文,沒有昏倒、也很難著性子看完幾篇吧。
適當的標注,也會影響到文章的解讀。就像是著名的「下雨天留客天天留我不留」,加上不同的標注後,可以產生迥然不同的解釋:「下雨天、留客天,天留、我不留」、「下雨天留客,天天留我不?留」。
碰到這類棘手的問題,一種方式是花錢請「專家」來標注。好吧,就算我們請一些「歷史系的專家或學生們」來對一些古文加上標注,也假設他們的標注是可接受的;接下來也還是會遇到中文處理的許多困難,其中之一就是「斷詞」。
一般來說,中英文都沒有斷字的問題。英文嘛,一個「字」(word) 是由 a, b, c 等英文字母組成,字與字之間可由空白、逗點等來區隔。例如,"This is a book." 這個句子,其中 "this"、 "is"、"a"、"book" 都是個別的「字」。而中文由於是方塊字,每一個字有獨立的字碼,也沒有斷字的問題。
但是,在中文裡,個別看每一個字,通常對內文的了解沒有什麼幫助;數個字連接起來成為一個「詞」之後,這個詞才會具備特定的意義。例如,「新」、「竹」如果分開來看,與「新竹」的意義,經常是完全不同的。
所以,中文有斷詞的問題。在前頭舉的古地契例子裡,「山埔」、「田薗」、「南港」、「鹿廚溪」都可以算作獨立的「詞」;但看起來像是個人名的「黃鼎愛斯」呢?是該斷作「黃鼎愛」、還是「黃鼎愛斯」?
可以想見,適當的標注,有助於斷詞的正確性。至少,我們知道一個詞不應橫跨由標點符號隔開的兩個子句。但是,即使有加上標點,想要適當地斷詞 --- 甚至斷出「地理名詞」、「人名」等特殊意義的詞彙 --- 都還是一項艱難的挑戰。
星期一, 11月 21, 2005
戴帽子問題
有沒有聽說過「戴帽子問題」?
問題的描述是這樣的:有三頂黑帽與兩頂白帽,自其中挑選三頂,讓 A、B、C 分別戴上一頂後,讓 A 排在 B 之前,B 排在 C 之前,形成一直線。每個人可以看到排在自己前面的人所戴的帽子顏色,但是卻看不到自己或排在自己後面的人所戴的帽子。現在,問 C 是否知道自己的帽子顏色,C 回答「不知」;接著問 B 是否知道自己戴的帽子顏色,B 也回答「不知」。最後,問 A 是否知道自己戴何色的帽子,A 卻回答「知道」。那麼,A 戴的帽子顏色是什麼呢?他又如何推斷出自己的帽色?
就像一般的邏輯問題,我們可以從證明論(Proof Theory;例如從「若 P 則 Q」以及「P」,可推斷出「Q」)或模型論(Model Theory;例如,窮舉所有可能性,然後說明,在所有的狀況下都成立)來著手解決。
一般的解答,都是利用證明論來解釋:
A 自問:我的帽子是白色的嗎?如果是,B 可以推論他自己的帽子是黑色的;因為若 B 的帽子也是白色的,C 就會看見兩頂白帽,從而推斷出自己戴黑色的帽子。然而,B 並沒有推斷出他自己戴什麼顏色的帽子,因此一開始的假設「A 帶白帽」不成立,因此可推斷出「A 帶黑帽」。
這個解答,因為用到數次「反證法」(Proof By Contradiction;用「非 P」為偽來證明「P」為真),因此很容易讓人有「喔,好聰明的解答啊」之感。不過,若換個角度,從模型論的觀點來看,或許可以得到更深刻的直觀:
 參考上圖,帶黑帽標示為小寫 b,戴白帽則標示為小寫 w。
參考上圖,帶黑帽標示為小寫 b,戴白帽則標示為小寫 w。
首先,我們知道,每個人頭上都帶有一頂帽子,因此 A, B, C 戴的帽子可能性,共有 8 種(參考圖 (1),每一列是一種可能性)。
但問題又敘述說,黑帽有三頂(或三頂以上),而白帽只有兩頂,因此不可能三人都戴著白帽(參考圖 (2),我們把三人都戴白帽的狀況用紅線刪除掉)。
接下來,問題又說:「問 C,回答不知自己所戴帽色」。因為 C 可以看見 A, B 所戴的帽子顏色,所以從圖 (2) 可知,A 與 B 不能夠同時戴有白帽(換句話說,A, B 若同時戴有白帽,則從圖 (2) 的第七列,C 可知自己戴著白帽)。所以,我們可以把 A, B 同時戴有白帽的狀況刪除(如圖 (3))。
然後,問題說,「接著,詢問 B,也不知自己戴那種顏色的帽子」。因為圖 (3) 說明了,若 A 戴白帽,則 B 必然戴著黑色帽子(圖 (3) 的前四列說明了,若 A 戴黑帽,B 可能戴黑帽、也可能戴白帽;而接下來的兩列則說明,若 A 戴著白帽,則 B 必然戴著黑帽)。不過,由於 B 回答他不知道自己的帽色,因此,我們可以把 A 戴白帽,B 戴黑帽的狀況刪除(參考圖 (4))。
最後,問 A 知不知道自己戴哪種顏色的帽子。因為在圖 (4) 的所有可能狀況中,A 都必然戴有黑帽,所以 A 可以很有自信地回答:「我戴黑色的帽子」。
問題的描述是這樣的:有三頂黑帽與兩頂白帽,自其中挑選三頂,讓 A、B、C 分別戴上一頂後,讓 A 排在 B 之前,B 排在 C 之前,形成一直線。每個人可以看到排在自己前面的人所戴的帽子顏色,但是卻看不到自己或排在自己後面的人所戴的帽子。現在,問 C 是否知道自己的帽子顏色,C 回答「不知」;接著問 B 是否知道自己戴的帽子顏色,B 也回答「不知」。最後,問 A 是否知道自己戴何色的帽子,A 卻回答「知道」。那麼,A 戴的帽子顏色是什麼呢?他又如何推斷出自己的帽色?
就像一般的邏輯問題,我們可以從證明論(Proof Theory;例如從「若 P 則 Q」以及「P」,可推斷出「Q」)或模型論(Model Theory;例如,窮舉所有可能性,然後說明,在所有的狀況下都成立)來著手解決。
一般的解答,都是利用證明論來解釋:
A 自問:我的帽子是白色的嗎?如果是,B 可以推論他自己的帽子是黑色的;因為若 B 的帽子也是白色的,C 就會看見兩頂白帽,從而推斷出自己戴黑色的帽子。然而,B 並沒有推斷出他自己戴什麼顏色的帽子,因此一開始的假設「A 帶白帽」不成立,因此可推斷出「A 帶黑帽」。
這個解答,因為用到數次「反證法」(Proof By Contradiction;用「非 P」為偽來證明「P」為真),因此很容易讓人有「喔,好聰明的解答啊」之感。不過,若換個角度,從模型論的觀點來看,或許可以得到更深刻的直觀:
 參考上圖,帶黑帽標示為小寫 b,戴白帽則標示為小寫 w。
參考上圖,帶黑帽標示為小寫 b,戴白帽則標示為小寫 w。首先,我們知道,每個人頭上都帶有一頂帽子,因此 A, B, C 戴的帽子可能性,共有 8 種(參考圖 (1),每一列是一種可能性)。
但問題又敘述說,黑帽有三頂(或三頂以上),而白帽只有兩頂,因此不可能三人都戴著白帽(參考圖 (2),我們把三人都戴白帽的狀況用紅線刪除掉)。
接下來,問題又說:「問 C,回答不知自己所戴帽色」。因為 C 可以看見 A, B 所戴的帽子顏色,所以從圖 (2) 可知,A 與 B 不能夠同時戴有白帽(換句話說,A, B 若同時戴有白帽,則從圖 (2) 的第七列,C 可知自己戴著白帽)。所以,我們可以把 A, B 同時戴有白帽的狀況刪除(如圖 (3))。
然後,問題說,「接著,詢問 B,也不知自己戴那種顏色的帽子」。因為圖 (3) 說明了,若 A 戴白帽,則 B 必然戴著黑色帽子(圖 (3) 的前四列說明了,若 A 戴黑帽,B 可能戴黑帽、也可能戴白帽;而接下來的兩列則說明,若 A 戴著白帽,則 B 必然戴著黑帽)。不過,由於 B 回答他不知道自己的帽色,因此,我們可以把 A 戴白帽,B 戴黑帽的狀況刪除(參考圖 (4))。
最後,問 A 知不知道自己戴哪種顏色的帽子。因為在圖 (4) 的所有可能狀況中,A 都必然戴有黑帽,所以 A 可以很有自信地回答:「我戴黑色的帽子」。
星期六, 11月 19, 2005
MySQL 也支援全文檢索
要提供一套查詢、檢索文件的系統,「全文檢索」(full-text retrieval;使用者輸入 query 字串,系統會把這個字串與文件的全文字串做比對,來找出符合 query 的文件們) 已經是不可或缺的要角了。
沒有人會質疑 Google 搜尋引擎的威力吧。事實上,Google 搜尋引擎做得最好的,就是能針對使用者下的 full-text query,在極短時間內,從非常大量的網路文件庫中,找出(並排序)「最有可能滿足使用者 query」的文件(URL、摘要、以及庫存檔)。
而實驗室既然想做一套「古契書的檢索系統」,當然也得提供全文檢索的功能。不過,現實面上,很容易就會處於抉擇的難點。難以抉擇的地方在哪兒呢?原來,我們的系統,並不只是想提供全文檢索,還希望利用其他的 metadata(好像是翻譯為「詮釋資料」吧)來增進檢索的效能。
於是,系統可能就得整合一套關連式資料庫 (RDDB)、與一套全文檢索系統(例如,Apache 的 Lucene project)。「整合」總是件吃力卻不怎麼討好的工作。
雖然 Microsoft SQL Server 很早就有同時提供 RDDB 與 full-text retrieval 的功能,但是實驗室老闆是很討厭 M$ 的;Oracle 有很好的 RDDB,但全文索引不是內建;因此,腦筋通常都會動到開放原始碼的 MySQL 上。
很高興地看見,MySQL 文件上,說它是支援全文檢索的。不過,實際跑了跑,就會有些沮喪:對中文資料而言,似乎行不通。手冊、甚至是網路文件上,對於如何處理中文的全文檢索,雖有片段的說明,卻缺乏完整的實例。
好吧,這又是一個需要做實驗(測試、並嘗試找到解答)的地方。「實驗室」嘛,就是得做做實驗,不是嗎?
透過以下這些步驟,應該可以讓 MySQL 處理中文的全文檢索:
沒有人會質疑 Google 搜尋引擎的威力吧。事實上,Google 搜尋引擎做得最好的,就是能針對使用者下的 full-text query,在極短時間內,從非常大量的網路文件庫中,找出(並排序)「最有可能滿足使用者 query」的文件(URL、摘要、以及庫存檔)。
而實驗室既然想做一套「古契書的檢索系統」,當然也得提供全文檢索的功能。不過,現實面上,很容易就會處於抉擇的難點。難以抉擇的地方在哪兒呢?原來,我們的系統,並不只是想提供全文檢索,還希望利用其他的 metadata(好像是翻譯為「詮釋資料」吧)來增進檢索的效能。
於是,系統可能就得整合一套關連式資料庫 (RDDB)、與一套全文檢索系統(例如,Apache 的 Lucene project)。「整合」總是件吃力卻不怎麼討好的工作。
雖然 Microsoft SQL Server 很早就有同時提供 RDDB 與 full-text retrieval 的功能,但是實驗室老闆是很討厭 M$ 的;Oracle 有很好的 RDDB,但全文索引不是內建;因此,腦筋通常都會動到開放原始碼的 MySQL 上。
很高興地看見,MySQL 文件上,說它是支援全文檢索的。不過,實際跑了跑,就會有些沮喪:對中文資料而言,似乎行不通。手冊、甚至是網路文件上,對於如何處理中文的全文檢索,雖有片段的說明,卻缺乏完整的實例。
好吧,這又是一個需要做實驗(測試、並嘗試找到解答)的地方。「實驗室」嘛,就是得做做實驗,不是嗎?
透過以下這些步驟,應該可以讓 MySQL 處理中文的全文檢索:
- 資料庫採用 UTF-8 編碼格式,以支援中文。此外,欲提供全文檢索,資料表必須採用 MyISAM 的型態。例如,CREATE TABLE table_name (...) ENGINE=MYISAM CHARACTER SET utf8 COLLATE utf8_general_ci;。
- 在資料表內建立欄位的全文索引。由於 MySQL 並不支援中文的斷字,因此我們目前還得新增一個欄位來儲存輔助全文檢索。例如,假設我們想對 DOC 欄位做全文索引,那麼除了 DOC 之外,我們還得新增一個(名稱自取的)DOC_FOR_FULLTEXT 欄位。然後,在 CREATE TABLE 時,加入 FULLTEXT (DOC_FOR_FULLTEXT) 來對這個輔助欄位的資料,建立全文索引。
- 將全文資料填入 DOC 欄位時,也將「自行斷字處理後的文件字串」填到 DOC_FOR_FULLTEXT 欄位裡。例如,假設要填入 DOC 欄位的全文是"新竹縣東興庄",那我們也同時將斷字後的 "新 竹 縣 東 興 庄 "(註:若字串內容為 UTF-16 Little Endian 編碼,利用 PHP 的 chunk_split() 可以在字串內,每隔兩個 bytes 插入一個空白字元 "\x20\0")填入 DOC_FOR_FULLTEXT 欄位。
- 執行 full-text SQL query 前,先執行 SET NAMES 'utf8'
- full-text SQL query 長得像這副模樣: SELECT * FROM
WHERE MATCH (DOC_FOR_FULLTEXT) AGAINST ($fulltext_query IN BOOLEAN MODE) 。其中,$fulltext_query 是一個對 user query 做過處理的字串。例如,若使用者輸入「新竹」,則 $fulltext_query 需要被處理為「'"新 竹"'」(注意:「新」與「竹」之間要有空白斷開,「新 竹」要用單引號框住雙引號;還有,不要忘記,SQL query 必須以 UTF-8 編碼的)。
星期三, 11月 16, 2005
Oh, it's obvious
在 Maryland 求學時,曾發生一件事情,讓我至今印象深刻。
當時,我是計算理論 (Theory of Computation) 的助教(但因為英文程度不夠好,並不是擔任需要上台授課的 TA;而只是改改作業與考卷、回答學生問題的 Grader)。有一天,一位頗有年紀的女學生,到助教室來問我一個問題(有些可惜,我已經忘記當時的題目是什麼了)。
那時討論到某段證明的一個癥結點。她問說:"Why?" 我回答 "Oh, it's obvious." 結果她滿臉苦惱,說了一段令我至今難忘的話:"It's obvious... I hate obvious!"(答案很顯然... 我厭恨這種「顯然」!)
至今我仍難忘她當時那副沮喪苦惱的表情。為什麼我忘不了這一幕?因為,事後我稍微仔細地想了想,發覺自己其實也不是那麼了解;換句話說,當時我的回答,算是自欺欺人的作為!
但為什麼當時沒有立即承認、只隱隱地告訴自己「嗯,有些不對勁...」呢?或許,一個很可能的原因是,雖然自己當時只是似懂非懂、一知半解;但有學生來問問題,實在無法大大方方、毫無羞愧地說:「我不懂、我不知道」。
也或許,這是難以避免的成長歷程。
在許多課本或者課堂上,都經常看見或聽到 "It's obvious" 或甚至 "It's trivial!" 的回答。雖然我們不太好懷疑,作者或者講課的老師,對問題的答案,是否真的感到「明顯、微不足道」,但我仍強烈地贊同「知之為知之,不知為不知」、甚至「打破沙鍋問到底」的求知態度。
下次,回答 "Oh, it's obvious" 前,讓我們先謹慎地問問自己,是不是「真的那麼顯而易見」罷。
當時,我是計算理論 (Theory of Computation) 的助教(但因為英文程度不夠好,並不是擔任需要上台授課的 TA;而只是改改作業與考卷、回答學生問題的 Grader)。有一天,一位頗有年紀的女學生,到助教室來問我一個問題(有些可惜,我已經忘記當時的題目是什麼了)。
那時討論到某段證明的一個癥結點。她問說:"Why?" 我回答 "Oh, it's obvious." 結果她滿臉苦惱,說了一段令我至今難忘的話:"It's obvious... I hate obvious!"(答案很顯然... 我厭恨這種「顯然」!)
至今我仍難忘她當時那副沮喪苦惱的表情。為什麼我忘不了這一幕?因為,事後我稍微仔細地想了想,發覺自己其實也不是那麼了解;換句話說,當時我的回答,算是自欺欺人的作為!
但為什麼當時沒有立即承認、只隱隱地告訴自己「嗯,有些不對勁...」呢?或許,一個很可能的原因是,雖然自己當時只是似懂非懂、一知半解;但有學生來問問題,實在無法大大方方、毫無羞愧地說:「我不懂、我不知道」。
也或許,這是難以避免的成長歷程。
在許多課本或者課堂上,都經常看見或聽到 "It's obvious" 或甚至 "It's trivial!" 的回答。雖然我們不太好懷疑,作者或者講課的老師,對問題的答案,是否真的感到「明顯、微不足道」,但我仍強烈地贊同「知之為知之,不知為不知」、甚至「打破沙鍋問到底」的求知態度。
下次,回答 "Oh, it's obvious" 前,讓我們先謹慎地問問自己,是不是「真的那麼顯而易見」罷。
星期日, 11月 13, 2005
談古契書資料處理:之二
上回談到古契書資料處理的一些棘手處。
在數位化的過程中,必須有人介入(掃瞄、打字等等)來產生「第一手的數位化資料」。這裡的重點是:有人介入,就會有錯誤產生。有時是看錯原籍,有時是打錯字詞,有時則是心不在焉、錯誤連連。此時,如果沒有安排「校對」的人力(據說,實驗室的古籍資料,是有安排校稿的人力;但從結果看來,似乎在品質上沒有改進太多),寫程式來做後續處理的人,就注定陷入一番苦戰了。
此外,如果沒有事先加以規範(但老實說,要「事先」就知道困難所在、並加以防範處理,是相當不容易的),即使看到同樣的字,不同的輸入人員可能會將其數位化成「形狀類似、但實際上不同」的字碼。例如,古契書裡並沒有使用阿拉伯數字,因此 40 會寫成「四〇」。從實際數位化的資料來看,至少有「四〇」、「四O」、「四0」、「四○」(這些「零」--- 〇O0○---看起來很相似吧?)等幾種不同的結果。
如果數位化資料只是供人閱讀,那倒還好;但若想對這些資料做進一步的處理,寫成不同的字碼,會導致寫程式做進一步處理時的困擾(例如,要搜尋文件中出現「四〇」字串),甚至會導致資料轉換的錯誤。
最後,還想再為「編碼」所導致的煩惱多說幾句。事實上,光是編碼、轉碼的問題,就夠資料處理的人員忙翻了。多種編碼共存也就算了,開發工具與國際組織們,往往也各支援不同的標準。例如,目前的 PHP 版本,就只支援 ISO-8859-1 編碼格式的程式;Windows 與 Java 內部則是採用 Unicode (不過,前者是 Little Endian 編碼;後者是 Big Endian 編碼);而現在流行的 XML 則建議使用 UTF-8。
怎麼這麼多種「標準」啊?從技術的觀點來看,每種編碼是各有其優缺點。但我有時不免會想:那些英語系國家的開發人員,大概不曉得處理這種編碼轉換是多麼令人厭煩吧。
在數位化的過程中,必須有人介入(掃瞄、打字等等)來產生「第一手的數位化資料」。這裡的重點是:有人介入,就會有錯誤產生。有時是看錯原籍,有時是打錯字詞,有時則是心不在焉、錯誤連連。此時,如果沒有安排「校對」的人力(據說,實驗室的古籍資料,是有安排校稿的人力;但從結果看來,似乎在品質上沒有改進太多),寫程式來做後續處理的人,就注定陷入一番苦戰了。
此外,如果沒有事先加以規範(但老實說,要「事先」就知道困難所在、並加以防範處理,是相當不容易的),即使看到同樣的字,不同的輸入人員可能會將其數位化成「形狀類似、但實際上不同」的字碼。例如,古契書裡並沒有使用阿拉伯數字,因此 40 會寫成「四〇」。從實際數位化的資料來看,至少有「四〇」、「四O」、「四0」、「四○」(這些「零」--- 〇O0○---看起來很相似吧?)等幾種不同的結果。
如果數位化資料只是供人閱讀,那倒還好;但若想對這些資料做進一步的處理,寫成不同的字碼,會導致寫程式做進一步處理時的困擾(例如,要搜尋文件中出現「四〇」字串),甚至會導致資料轉換的錯誤。
最後,還想再為「編碼」所導致的煩惱多說幾句。事實上,光是編碼、轉碼的問題,就夠資料處理的人員忙翻了。多種編碼共存也就算了,開發工具與國際組織們,往往也各支援不同的標準。例如,目前的 PHP 版本,就只支援 ISO-8859-1 編碼格式的程式;Windows 與 Java 內部則是採用 Unicode (不過,前者是 Little Endian 編碼;後者是 Big Endian 編碼);而現在流行的 XML 則建議使用 UTF-8。
怎麼這麼多種「標準」啊?從技術的觀點來看,每種編碼是各有其優缺點。但我有時不免會想:那些英語系國家的開發人員,大概不曉得處理這種編碼轉換是多麼令人厭煩吧。
星期四, 11月 10, 2005
技能、態度、注意力
教育(或者說專業教育)的主要目的是什麼呢?
"The main purpose of professional education is development of skills; the main purpose of education in subjects like mathematics, physics or philosophy is development of attitudes." Discrete Thoughts 的作者如是說。他們認為,專業教育是要發展技能,而數學、物理、哲學等科目的教育目的,則是在發展態度。(喔,或許,理學院與工學院的差異也在於此?)
在一本小書裡,則看到這樣的話:法國的思想家 Simone Weil 認為,注意力的培養,是學校教學的真正目的;它是唯一的意義所在,其他的意義都是第二位的。(且不說獲取知識就需要專心一致;如果不能夠聚精會神、專注地做某件事情,再多的知識又有什麼用呢?)
接受了十幾年的教育,我們在技能、態度、與注意力上,是否學到了什麼?
"The main purpose of professional education is development of skills; the main purpose of education in subjects like mathematics, physics or philosophy is development of attitudes." Discrete Thoughts 的作者如是說。他們認為,專業教育是要發展技能,而數學、物理、哲學等科目的教育目的,則是在發展態度。(喔,或許,理學院與工學院的差異也在於此?)
在一本小書裡,則看到這樣的話:法國的思想家 Simone Weil 認為,注意力的培養,是學校教學的真正目的;它是唯一的意義所在,其他的意義都是第二位的。(且不說獲取知識就需要專心一致;如果不能夠聚精會神、專注地做某件事情,再多的知識又有什麼用呢?)
接受了十幾年的教育,我們在技能、態度、與注意力上,是否學到了什麼?
星期二, 11月 08, 2005
摸著牆走迷宮
在迷宮裡,要如何找到出口呢?
很多人應該都聽過「摸著牆壁走」的方法:只要一直摸著右邊(或者左邊)的牆走,最後一定可以走出迷宮(例如,「迷宮、黃金比、索馬立方體」這本書,就有提到這種策略)。
但是,為什麼這種策略可以行得通呢?
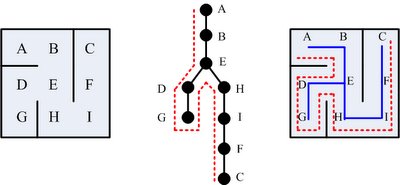
原來,在概念上,沿著一邊的牆壁走,就相當於在執行「深度優先搜尋」(DFS, depth-first search)。參考上面的圖形,應該可以給我們一些感覺:給定左側的小迷宮,目標是由 A 點走到 C 點;而迷宮的樹狀圖(在此先假設迷宮任兩點間只有唯一的一條路)如中間圖所示:最右側的圖,則畫出「摸著右側牆壁走」的路線(迷宮中的藍線,就相當於樹狀圖)。
這樣的走迷宮策略,有什麼限制嗎?如果,迷宮是多連通(multiple-connected,兩個迷宮格之間,不必然只有唯一的路)的,那怎麼辦呢?
一般來說,即使迷宮是多連通的,「摸著牆走迷宮」的策略依然行得通。例如,在下面的圖形裡,我們要從入口 A 點,走到出口 D 點。因為 F-E-I-M-N-O-P-L-K-G-F 構成一個圈 (circle, loop),因此從 F 到 G 有兩條路可走:F-E-I-M-N-O-P-L-K-G 或者 F-G。中間的圖形,說明了沿著右側牆壁走,依然可以從 A 點走到 D 點。(事實上,只要「迷宮出入口」不在這個圈子內 --- 例如 J 點 --- 這個方法就行得通。)
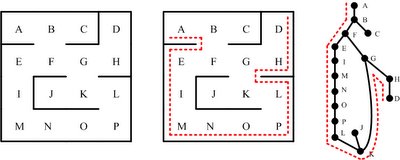
像這樣的圖說,當然不能算是證明。不過,有了直觀後,通常證明就呼之欲出了。有趣的是,這樣的走迷宮策略,與現實生活處理問題的方式,還有著可類比之處:有 時,我們會找不到方法來解決現實環境碰到的問題。這種時候,或許只能依靠「摸著牆壁走」的方式,藉由拓展對問題(空間)的認知,一步一步地走出迷宮呢。
很多人應該都聽過「摸著牆壁走」的方法:只要一直摸著右邊(或者左邊)的牆走,最後一定可以走出迷宮(例如,「迷宮、黃金比、索馬立方體」這本書,就有提到這種策略)。
但是,為什麼這種策略可以行得通呢?

原來,在概念上,沿著一邊的牆壁走,就相當於在執行「深度優先搜尋」(DFS, depth-first search)。參考上面的圖形,應該可以給我們一些感覺:給定左側的小迷宮,目標是由 A 點走到 C 點;而迷宮的樹狀圖(在此先假設迷宮任兩點間只有唯一的一條路)如中間圖所示:最右側的圖,則畫出「摸著右側牆壁走」的路線(迷宮中的藍線,就相當於樹狀圖)。
這樣的走迷宮策略,有什麼限制嗎?如果,迷宮是多連通(multiple-connected,兩個迷宮格之間,不必然只有唯一的路)的,那怎麼辦呢?
一般來說,即使迷宮是多連通的,「摸著牆走迷宮」的策略依然行得通。例如,在下面的圖形裡,我們要從入口 A 點,走到出口 D 點。因為 F-E-I-M-N-O-P-L-K-G-F 構成一個圈 (circle, loop),因此從 F 到 G 有兩條路可走:F-E-I-M-N-O-P-L-K-G 或者 F-G。中間的圖形,說明了沿著右側牆壁走,依然可以從 A 點走到 D 點。(事實上,只要「迷宮出入口」不在這個圈子內 --- 例如 J 點 --- 這個方法就行得通。)
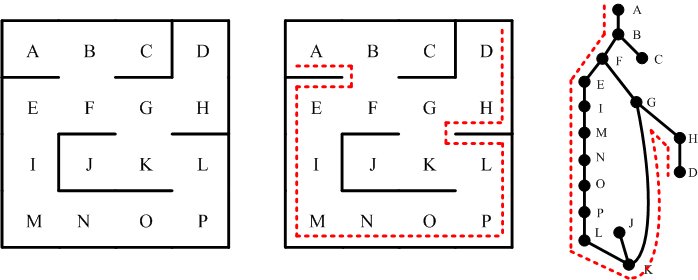
像這樣的圖說,當然不能算是證明。不過,有了直觀後,通常證明就呼之欲出了。有趣的是,這樣的走迷宮策略,與現實生活處理問題的方式,還有著可類比之處:有 時,我們會找不到方法來解決現實環境碰到的問題。這種時候,或許只能依靠「摸著牆壁走」的方式,藉由拓展對問題(空間)的認知,一步一步地走出迷宮呢。
星期四, 11月 03, 2005
談古契書資料處理:之一
這一陣子在「想寫的文章」上進展頗為遲緩 --- 那我在忙些什麼啊?
嗯,一言難盡。簡單地說,是在做實驗室古契書電子檔的一些資料處理實驗。
實驗室裡,多年來持續在進行一個 THDL (Taiwan History Digital Library,台灣歷史數位化圖書館)的計畫。希望能藉由電腦科技與數位化古籍資料,來改善歷史學者(與一般民眾)對台灣歷史的研究與了解。
因此,實驗室有著許多「花不少錢」請人數位化的台灣古契書資料。然而,光是「資料數位化」這個過程,其實就隱含著許多困難。例如,古契書常常會有一些奇特的字,沒有被收錄到 Big5 或者 Unicode 裡,而這就產生了「缺字問題」。
除了這個相對明顯的「缺字問題」外,還有一些努力(或者說是苦工)就經常被忽視。例如,將這些不同 corpus(文獻集)的資料數位化時,通常都是請人「把文件內容掃描、打字」來取得數位資訊的,因而就產生了「資料彙整」的問題。例如,若打字人員是用 Microsoft Word 來鍵入資料,那麼我們最後還是得寫程式來將文字資料從 Word 文件中轉出。
對文件做資料格式轉換,聽起來也沒有什麼。不過,它背後還隱含著文件編碼(Big5、UTF-16 Big Endian、UTF-16 Little Endian、UTF-8)的假設。於是,用 Java 寫的轉換程式,輸出就是 UTF-16 Big Endian 的格式 -- 這讓我稍嫌老舊的 UltraEdit「無法正常編輯檢視」,於是我就得花點力氣再將它們再轉成 UTF-16 Little Endian 編碼。
另一方面,寫程式從 Word 文件將文字資料轉出,有可能對某些文件處理失敗。通常,這部分的努力很少得到「長官」合適的重視,也因此讓「資料處理」成為一件吃力不討好的差事。
經過一些資料檢視與實驗,我對於實驗室學弟妹們的辛苦(做了很多雜事,卻沒有被 appreciate 到的感覺),其實是有一份理解的。
嗯,一言難盡。簡單地說,是在做實驗室古契書電子檔的一些資料處理實驗。
實驗室裡,多年來持續在進行一個 THDL (Taiwan History Digital Library,台灣歷史數位化圖書館)的計畫。希望能藉由電腦科技與數位化古籍資料,來改善歷史學者(與一般民眾)對台灣歷史的研究與了解。
因此,實驗室有著許多「花不少錢」請人數位化的台灣古契書資料。然而,光是「資料數位化」這個過程,其實就隱含著許多困難。例如,古契書常常會有一些奇特的字,沒有被收錄到 Big5 或者 Unicode 裡,而這就產生了「缺字問題」。
除了這個相對明顯的「缺字問題」外,還有一些努力(或者說是苦工)就經常被忽視。例如,將這些不同 corpus(文獻集)的資料數位化時,通常都是請人「把文件內容掃描、打字」來取得數位資訊的,因而就產生了「資料彙整」的問題。例如,若打字人員是用 Microsoft Word 來鍵入資料,那麼我們最後還是得寫程式來將文字資料從 Word 文件中轉出。
對文件做資料格式轉換,聽起來也沒有什麼。不過,它背後還隱含著文件編碼(Big5、UTF-16 Big Endian、UTF-16 Little Endian、UTF-8)的假設。於是,用 Java 寫的轉換程式,輸出就是 UTF-16 Big Endian 的格式 -- 這讓我稍嫌老舊的 UltraEdit「無法正常編輯檢視」,於是我就得花點力氣再將它們再轉成 UTF-16 Little Endian 編碼。
另一方面,寫程式從 Word 文件將文字資料轉出,有可能對某些文件處理失敗。通常,這部分的努力很少得到「長官」合適的重視,也因此讓「資料處理」成為一件吃力不討好的差事。
經過一些資料檢視與實驗,我對於實驗室學弟妹們的辛苦(做了很多雜事,卻沒有被 appreciate 到的感覺),其實是有一份理解的。
星期二, 11月 01, 2005
一無所有
日子過得很快,回鍋做博士後研究,也滿一個月了。
這個月來,對實驗室的環境漸漸進入狀況。主要的工作,就是在實驗室幫助學弟妹們討論、釐清研究主題與方向。此外,旁聽了一場座談會,並且代替項老師主持了兩次實驗室 meetings。
就像是貓所描述的「四十歲中年危機」,自己這一陣子,在自我認同、自我觀念上,確實有些變化。幾天前帶寶寶到中正紀念堂參觀「廣場藝術節」展覽,意外碰到大學同學老鮑,他的孩子已經十歲了。閒聊許久,他說,在這個年紀會這樣應屬正常,他同樣地也對生命價值感到困惑。
「是否我真的一無所有?黑暗之中沈默地探索你的手。是否我真的一無所有,明天的我又要到哪裡停泊...」大學口的重順餐廳,傳來一陣陣王傑的歌聲。這可是我大學時代的歌曲呢,想不到連續幾次在重順用餐,都聽到這首老歌。
哦,是否我真的一無所有?如果不是,那我又擁有了些什麼?
這個月來,對實驗室的環境漸漸進入狀況。主要的工作,就是在實驗室幫助學弟妹們討論、釐清研究主題與方向。此外,旁聽了一場座談會,並且代替項老師主持了兩次實驗室 meetings。
就像是貓所描述的「四十歲中年危機」,自己這一陣子,在自我認同、自我觀念上,確實有些變化。幾天前帶寶寶到中正紀念堂參觀「廣場藝術節」展覽,意外碰到大學同學老鮑,他的孩子已經十歲了。閒聊許久,他說,在這個年紀會這樣應屬正常,他同樣地也對生命價值感到困惑。
「是否我真的一無所有?黑暗之中沈默地探索你的手。是否我真的一無所有,明天的我又要到哪裡停泊...」大學口的重順餐廳,傳來一陣陣王傑的歌聲。這可是我大學時代的歌曲呢,想不到連續幾次在重順用餐,都聽到這首老歌。
哦,是否我真的一無所有?如果不是,那我又擁有了些什麼?
訂閱:
文章 (Atom)